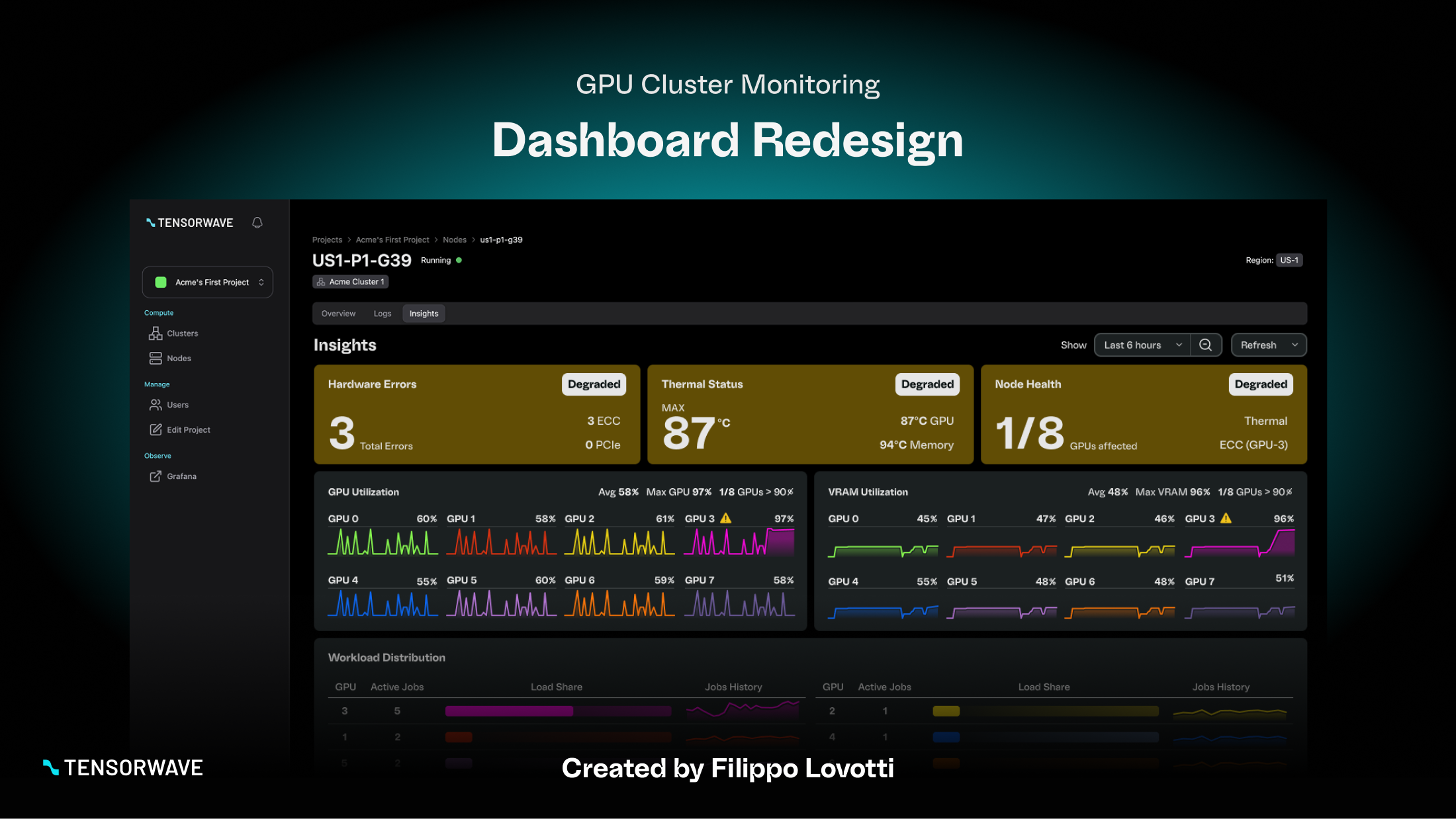
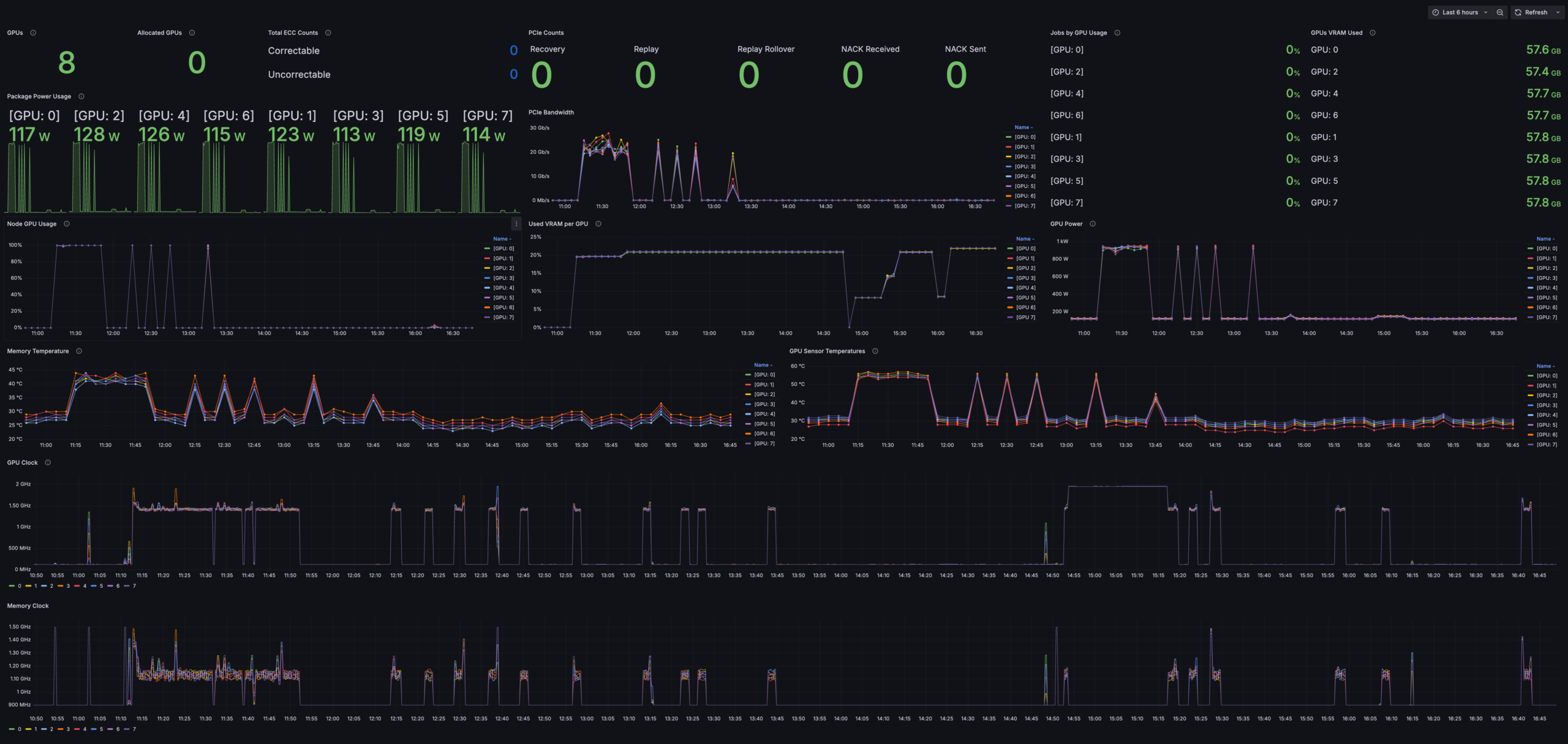
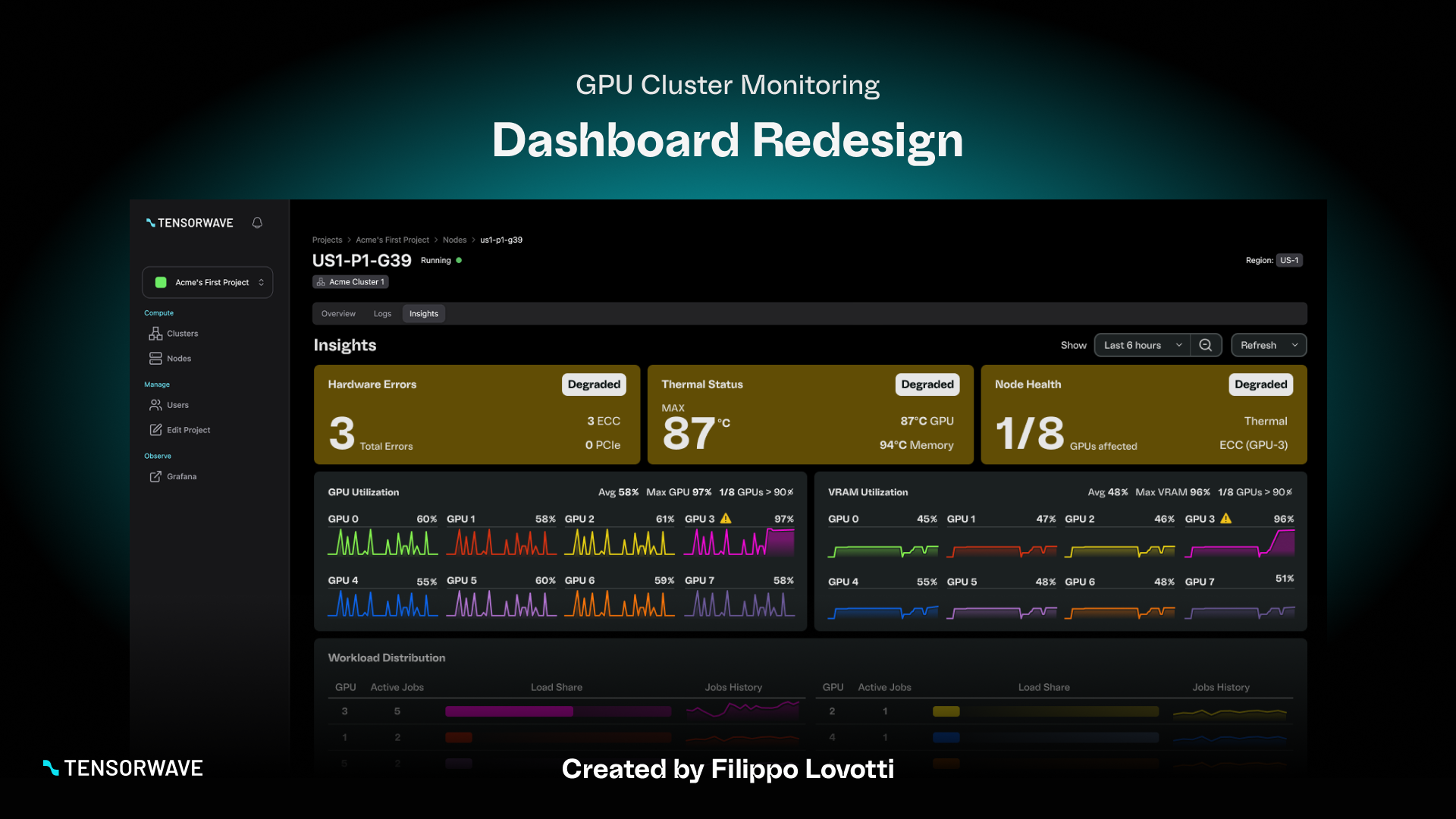
I treated this as an operational decision-making interface, not a “chart cleanup” exercise. My focus was to preserve critical data while reorganizing the experience around the questions users are trying to answer in real time.
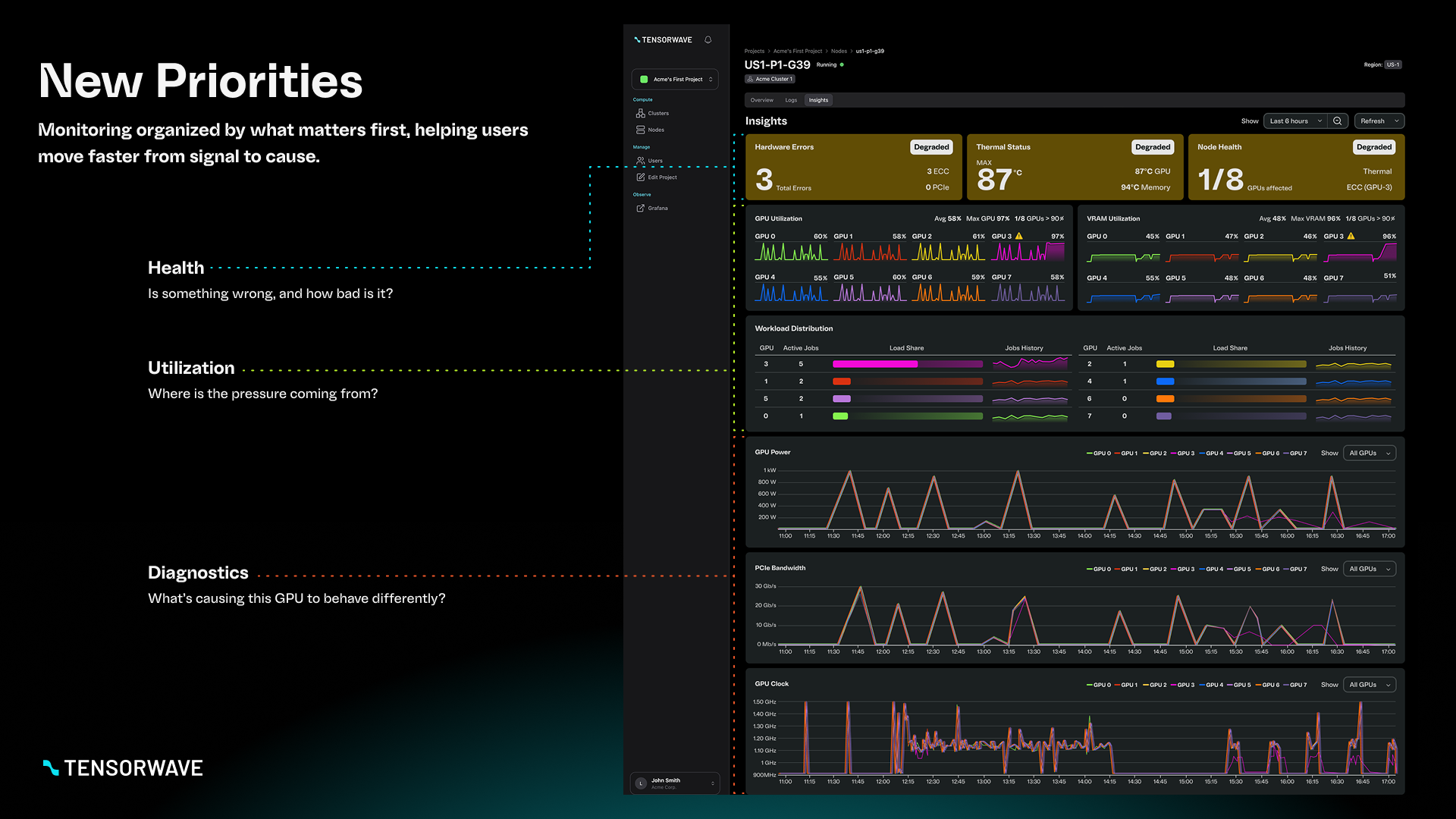
1) Information hierarchy
I reorganized the dashboard into three clear layers:
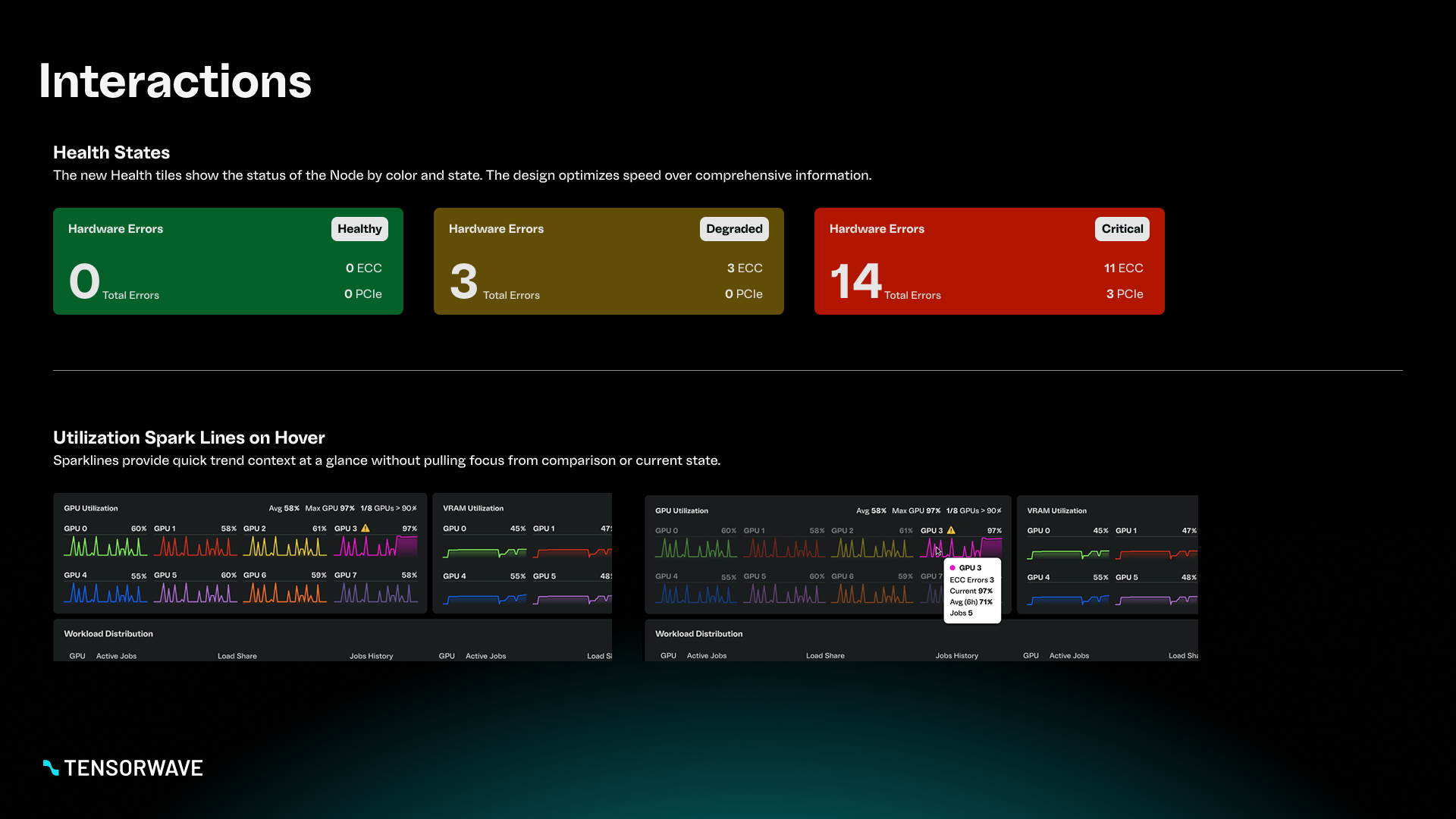
- Health: Are there any issues requiring attention right now?
- Utilization: Where is capacity being consumed or constrained?
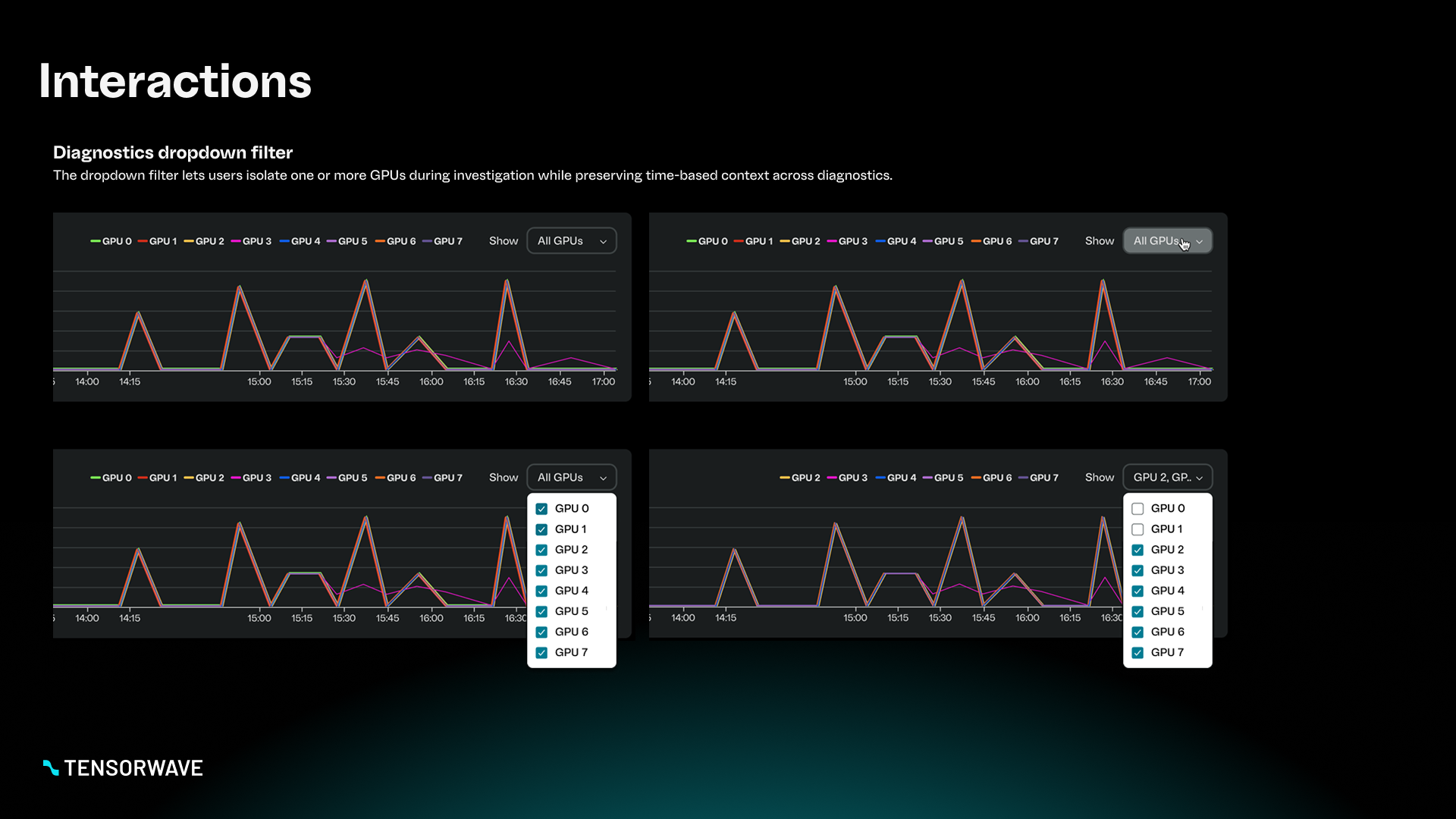
- Diagnostics: What’s causing abnormal behavior and where is it happening?
This structure makes the dashboard faster to scan while still supporting deeper investigation.
2) Visualization choices
I selected visualization types based on how the data is used:
- High-level status tiles for rapid health scanning
- Compact trend visuals for comparing utilization across GPUs at a glance
- Time-series diagnostics charts to support investigation and pattern recognition
3) Key design decision
My biggest change was shifting from a flat, metric-first layout to a question-first layout that supports operational workflows: detect → assess → investigate.
See my thinking process in the Figjam below.